Recursion
In Haskell we essentially use recursion, this mean defining a function using itself definition.
A recursive function is, for example the factorial:

in haskell we define it like that:
fact 0 = 1 fact n = n * fact (n-1)
As you can see Haskell is authentic mathematic, pure functional language.
My point here is to show you the magic of the function 
ok…
Seeing the magic
The definition of the function 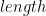
length [] = 0 length (h:t) = 1 + length t
The definition of the function 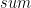
sum [] = 0 sum (h:t) = h + sum t
And the definition of the function 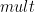
mult [] = 1 mult (h:t) = h * mult t
As you can see in all three definitions we have a pattern and we can generalize it:
functionName [] = stopCase functionName (h:t) = constant operator (functionName t)
We always need the stopping case of the function!
And the same happens in other functions like 
reverse [] = [] reverse (h:t) = reverse t ++ [h]
In this case we have:
functionName [] = stopCase functionName (h:t) = (functionName t) operator constant
So, we will always use the function applied to the tail of the list!
If we use some of lambda notation we can see one more pattern, the real one:
sum [] = 0 sum (h:t) = (a b -> a + b) h (sum t) reverse [] = [] reverse (h:t) = (a b -> b ++ [a]) h (reverse t)
Our lambdas functions have arity 2, because those are the parts in which we can see the lists (head + tail).
Now we can generalize even more, considering 
functionName [] = stopCase functionName (h:t) = function h (functionName t)
well, that’s not right for Haskell. Because it doesn’t know what 
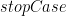
functionName function stopCase [] = stopCase
functionName function stopCase (h:t)
= function h (functionName function stopCase t)
Et voilá.
In fact the last definition is the true one for
Functions with foldr’s
Well… Now we can redefine previous functions just with foldr’s:
length l = foldr (a b -> 1 + b) 0 l sum l = foldr (+) 0 l mult l = foldr (*) 1 l reverse l = foldr (a b -> b ++ [a]) [] l
And all the functions over list’s…
and l = foldr (&&) True l or l = foldr (||) False l
More magic
Foldr is more magical than this, it is one catamorphism! A Catamorphism over this data type:
data [a] = [] | a : [a]
Haskell List’s!
That means that
Foldr also allows you to use Pointfree notation, witch I like. Formal explanation.
length = foldr (a b -> 1 + b) 0
More foldr’s
We can also write foldr’s functions to every data type that we create, and “explain” how recursive patterns works for our new data type:
data BTree a where
Empty :: BTree a
Node :: a -> BTree a -> BTree a -> BTree a
foldrBTree :: (a -> b -> b -> b) -> b -> BTree a -> b
foldrBTree op k Empty = k
foldrBTree op k (Node a l r) = op a (foldrBTree op k l) (foldrBTree op k r)
Now if we have a Binary Tree and want to know how many nodes it has, we just have to do this:
countNodes = foldrBTree (\a nodesLeft nodesRight ->a+nodesLeft+nodesRight) 0
If we want to know how many Empty’s our tree has:
countEmpty = foldrBTree (\_ nodesLeft nodesRight -> nodesLeft + nodesRight) 1
and so on…
Fold’s are really a genuine help for your code.
Later on I will talk more about catamorphisms…






