A couple of years ago, during my masters on Formal Methods I have been working with automatic provers and I also used Frama-C, this is a tool that allow the user to prove C code directly in the source code, using a special notation in the comments, called ACSL notation.
Frama-C allows you to make two kinds of proofs, security and safety ones. The safety ones are related with arrays index out of bounds access, and so. This kind of proofs are related to the language itself and they are easy to do if you use loop invariants, pre and post conditions.
If you use a high level language, like JAVA you won’t have almost none safety problems.
Because C is too close to machine level code, we can do things that we do not intend (or maybe we do and we use C exactly because it allows this kind of things). For example:
// foo.c file
#include <stdio.h>
int main() {
char *a = "I like you";
char *b = "I hate you";
if(&a < &b) a = *(&a + 1);
else a = *(&a - 1);
printf("%s\n", a);
}
As you can see, I never used the 
[ulissesaraujocosta@maclisses:c]-$ gcc -o foo foo.c [ulissesaraujocosta@maclisses:c]-$ ./foo I hate you
This lack of security of language C is one of the reasons we need to write safety statements. Of course this kind of things is why C is so fast and powerful, the person in charge is always the programmer. If you are interested in this kind of tricks and want to understand more about this and smashing the stack and so, feel free to read more posts in my blog about this subject.
The other kind of statements (security ones) are related to the functionality of the program and that’s basically where the problem or the effort is, I will talk about this later on. First let’s see the algorithm and the implementation in C.
Code
The algorithm I use here is just a simple example. I used bubble sort, this is a sort algorithm not very efficient, but it uses none more memory then the needed to store the structure you want to sort.
To get a visual understanding of the algorithm (and to see it inefficiency) check out this youtube video.
This is the implementation of the algorithm:
void swap(int *i, int *j) {
int tmp = *i;
*i = *j;
*j = tmp;
}
void bubbleSort(int *vector, int tam) {
int j, i;
j = i = 0;
for(i=0; i<tam; i++) {
for(j=0; j<tam-i-1; j++) {
g_swap = 0;
if (vector[j] > vector[j+1]) {
swap(&vector[j],&vector[j+1]);
}
}
}
}
Pre, Post conditions and thinking formally
So, as you can see in the video (or in the code) the algorithm is pretty much simple, we pick the 

We have as pre conditions: The size of the 




Ans as pos conditions we must ensure that the array is sorted ( I will talk predicate this later).
You may think that this by itself is enough to make a complete proof, but you are wrong. Image that my function clear all the elements in the array and fill the array with 
So, we need to say more… First thing that can pop to your head is OK, we will say that we have the same numbers in the beginning and in the end and you write this:

In fact this is closer (not yet right), imagine that you give as input:



So, the solution if to make a 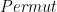
So, this are the post conditions:


Frama-C is so cool because for example at the pos condition if we want to refer to the state in the beginning (before call the function) we use 

Predicates
So, here is the 

/*@ predicate Sorted{L}(int a[], integer l, integer h) =
@ \forall integer i; l <= i < h ==> a[i] <= a[i+1];
@*/
The 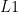


We write multiple rules for the permutation, reflection, symmetry, transitivity and finally the most important one, the 
/*@ inductive Permut{L1,L2}(int a[], integer l, integer h) {
@ case Permut_refl{L}:
@ \forall int a[], integer l, h; Permut{L,L}(a, l, h) ;
@ case Permut_sym{L1,L2}:
@ \forall int a[], integer l, h;
@ Permut{L1,L2}(a, l, h) ==> Permut{L2,L1}(a, l, h) ;
@ case Permut_trans{L1,L2,L3}:
@ \forall int a[], integer l, h;
@ Permut{L1,L2}(a, l, h) && Permut{L2,L3}(a, l, h) ==>
@ Permut{L1,L3}(a, l, h) ;
@ case Permut_swap{L1,L2}:
@ \forall int a[], integer l, h, i, j;
@ l <= i <= h && l <= j <= h && Swap{L1,L2}(a, i, j) ==>
@ Permut{L1,L2}(a, l, h) ;
@ }
@
@ predicate Swap{L1,L2}(int a[], integer i, integer j) =
@ \at(a[i],L1) == \at(a[j],L2)
@ && \at(a[j],L1) == \at(a[i],L2)
@ && \forall integer k; k != i && k != j ==> \at(a[k],L1) == \at(a[k],L2);
@*/
So, as you can see the bubble sort function itself have 18 lines of code, and in the end with the annotations for the proof we end with 90 lines, but we proved it!
Thoughts
My main point here is to show the thinking we need to have if we want to prove code in general. Pick what language you want, this is the easiest way you will have to prove software written in C. Sometimes if your functions are too complex you may need to prove it manually. The problem is not on the Frama-C side, Frama-C only generates the proof obligations to feed to automatic provers, like Yices, CVC3, Simplify, Z3, Alt-Ergo and so.
My point here is to show the cost of proving software. Proving software, specially if the language is too low level (like C – you need to care about a lot more things) is hard work and is not easy to a programmer without theoretical knowledge.
On the other side, you end up with a piece of software that is proved. Of course this proof is always requirements oriented, ny that I mean: if the requirements are wrong and the program is not doing what you expect the proof is along with that.
I do not stand to proof of all the code on the planet, but the proper utilization of FM (formal methods) tools for critical software.
I steel been using Frama-C since I learned it in 2009, nowadays I use it for small critical functions (because I want, I’m not encouraged to do so) and I have to say that the use of FM in the industry is far. As I told you Frama-C is the easiest automatic proof tool you will find at least that I know.
Talking with Marcelo Sousa about the use of FM in industry, we came to the conclusion that the people that are making this kind of tools and have the FM knowledge don’t make companies. I think if more brilliant people like John Launchbury make companies, definitely FM will be more used.
Source code
Here is all the code together if you want to test it:
// #include <stdio.h>
/*@ predicate Sorted{L}(int a[], integer l, integer h) =
@ \forall integer i; l <= i < h ==> a[i] <= a[i+1];
@
@ predicate Swap{L1,L2}(int a[], integer i, integer j) =
@ \at(a[i],L1) == \at(a[j],L2)
@ && \at(a[j],L1) == \at(a[i],L2)
@ && \forall integer k; k != i && k != j ==> \at(a[k],L1) == \at(a[k],L2);
@*/
/*@ inductive Permut{L1,L2}(int a[], integer l, integer h) {
@ case Permut_refl{L}:
@ \forall int a[], integer l, h; Permut{L,L}(a, l, h) ;
@ case Permut_sym{L1,L2}:
@ \forall int a[], integer l, h;
@ Permut{L1,L2}(a, l, h) ==> Permut{L2,L1}(a, l, h) ;
@ case Permut_trans{L1,L2,L3}:
@ \forall int a[], integer l, h;
@ Permut{L1,L2}(a, l, h) && Permut{L2,L3}(a, l, h) ==>
@ Permut{L1,L3}(a, l, h) ;
@ case Permut_swap{L1,L2}:
@ \forall int a[], integer l, h, i, j;
@ l <= i <= h && l <= j <= h && Swap{L1,L2}(a, i, j) ==>
@ Permut{L1,L2}(a, l, h) ;
@ }
@*/
/*@ requires \valid(i) && \valid(j);
@ //assigns *i, *j; //BUG 0000080: Assertion failed in jc_interp_misc.ml
@ ensures \at(*i,Old) == \at(*j,Here) && \at(*j,Old) == \at(*i,Here);
@*/
void swap(int *i, int *j) {
int tmp = *i;
*i = *j;
*j = tmp;
}
/*@ requires tam > 0;
@ requires \valid_range(vector,0,tam-1);
@ ensures Sorted{Here}(vector, 0, tam-1);
@ ensures Permut{Old,Here}(vector,0,tam-1);
@*/
void bubbleSort(int *vector, int tam) {
int j, i;
j = i = 0;
//@ ghost int g_swap = 0;
/*@ loop invariant 0 <= i < tam;
@ loop invariant 0 <= g_swap <= 1;
//last i+1 elements of sequence are sorted
@ loop invariant Sorted{Here}(vector,tam-i-1,tam-1);
//and are all greater or equal to the other elements of the sequence.
@ loop invariant 0 < i < tam ==> \forall int a, b; 0 <= b <= tam-i-1 <= a < tam ==> vector[a] >= vector[b];
@ loop invariant 0 < i < tam ==> Permut{Pre,Here}(vector,0,tam-1);
@ loop variant tam-i;
@*/
for(i=0; i<tam; i++) {
//@ ghost g_swap = 0;
/*@ loop invariant 0 <= j < tam-i;
@ loop invariant 0 <= g_swap <= 1;
//The jth+1 element of sequence is greater or equal to the first j+1 elements of sequence.
@ loop invariant 0 < j < tam-i ==> \forall int a; 0 <= a <= j ==> vector[a] <= vector[j+1];
@ loop invariant 0 < j < tam-i ==> (g_swap == 1) ==> Permut{Pre,Here}(vector,0,tam-1);
@ loop variant tam-i-j-1;
@*/
for(j=0; j<tam-i-1; j++) {
g_swap = 0;
if (vector[j] > vector[j+1]) {
//@ ghost g_swap = 1;
swap(&vector[j],&vector[j+1]);
}
}
}
}
/*@ requires \true;
@ ensures \result == 0;
@*/
int main(int argc, char *argv[]) {
int i;
int v[9] = {8,5,2,6,9,3,0,4,1};
bubbleSort(v,9);
// for(i=0; i<9; i++)
// printf("v[%d]=%d\n",i,v[i]);
return 0;
}
If you are interested in the presentation me and pedro gave at our University, here it is:

 or
or  . Because we glue the ana and cata together into a single recursive pattern.
. Because we glue the ana and cata together into a single recursive pattern.  and
and 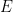 could be some data type your function need. With this post I will try to show you more hylomorphisms over some different data types to show you the power of this field.
could be some data type your function need. With this post I will try to show you more hylomorphisms over some different data types to show you the power of this field. . In Haskell we can represent
. In Haskell we can represent  we draw the following diagram:
we draw the following diagram:![[(h)]](https://s0.wp.com/latex.php?latex=%5B%28h%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Before that I’m going to specify the strategy to define factorial. I’m going to use the diagram’s again, remember that type
. Before that I’m going to specify the strategy to define factorial. I’m going to use the diagram’s again, remember that type  is equivalent to Haskell
is equivalent to Haskell  :
: as my intermediate structure, and I’ve already define the names of my gen functions
as my intermediate structure, and I’ve already define the names of my gen functions  to the catamorphism and
to the catamorphism and 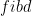 to the anamorphism. The strategy I prefer, is do all the hard work in the anamorphism, so here the gen
to the anamorphism. The strategy I prefer, is do all the hard work in the anamorphism, so here the gen 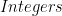 , so now we can make a more specific diagram to represent our solution:
, so now we can make a more specific diagram to represent our solution:![[Integer]](https://s0.wp.com/latex.php?latex=%5BInteger%5D&bg=ffffff&fg=000000&s=0&c=20201002) to represent my intermediate data, and I’ve already define the names of my gen functions
to represent my intermediate data, and I’ve already define the names of my gen functions  to the catamorphism and
to the catamorphism and  to the anamorphism. Another time, that I do all the work with the anamorphism, letting the catamorphism with little things to do (just multiply). I’m start to show you the catamorphism first:
to the anamorphism. Another time, that I do all the work with the anamorphism, letting the catamorphism with little things to do (just multiply). I’m start to show you the catamorphism first:![[]](https://s0.wp.com/latex.php?latex=%5B%5D&bg=ffffff&fg=000000&s=0&c=20201002) empty list.
empty list. structure:
structure: is:
is: to be a sequence of pairs
to be a sequence of pairs  where n is the number of disks,
where n is the number of disks,  is a disk number and
is a disk number and  are directions. Disks are numbered from
are directions. Disks are numbered from  onwards, disk
onwards, disk  representing a clockwise movement and
representing a clockwise movement and  an anti-clockwise movement. The pair
an anti-clockwise movement. The pair 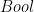 and
and  :
: , replacing that by the proper notation we have:
, replacing that by the proper notation we have: ![[|f,h|]~=~(|f|)~\circ~[(h)]](https://s0.wp.com/latex.php?latex=%5B%7Cf%2Ch%7C%5D%7E%3D%7E%28%7Cf%7C%29%7E%5Ccirc%7E%5B%28h%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 , what we are trying to say is that the intermediate structure of our combination of catamorphism and anamorphism is that data type
, what we are trying to say is that the intermediate structure of our combination of catamorphism and anamorphism is that data type  function works over lists. So the first thing to do, is draw the respective anamorphism from
function works over lists. So the first thing to do, is draw the respective anamorphism from ![[a]](https://s0.wp.com/latex.php?latex=%5Ba%5D&bg=ffffff&fg=000000&s=0&c=20201002) to
to  :
: with type:
with type:![h : [a] \rightarrow 1 + a \times [a] \times [a]](https://s0.wp.com/latex.php?latex=h+%3A+%5Ba%5D+%5Crightarrow+1+%2B+a+%5Ctimes+%5Ba%5D+%5Ctimes+%5Ba%5D&bg=ffffff&fg=000000&s=0&c=20201002) , or in Haskell
, or in Haskell ![h :: [a] \rightarrow Either () (a, ([a], [a]))](https://s0.wp.com/latex.php?latex=h+%3A%3A+%5Ba%5D+%5Crightarrow+Either+%28%29+%28a%2C+%28%5Ba%5D%2C+%5Ba%5D%29%29&bg=ffffff&fg=000000&s=0&c=20201002)
 :
: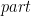 , it process all the list finding the elements that satisfy the condition
, it process all the list finding the elements that satisfy the condition  , to put them in the left side of the tuple, and the others into the right side.
, to put them in the left side of the tuple, and the others into the right side.![a + a \times [a] \times [a]](https://s0.wp.com/latex.php?latex=a+%2B+a+%5Ctimes+%5Ba%5D+%5Ctimes+%5Ba%5D&bg=ffffff&fg=000000&s=0&c=20201002) , which is very simple, as as shown by the code.
, which is very simple, as as shown by the code. :
: , i can say:
, i can say: , and composition
, and composition  functions.
functions. :
: as a the following function:
as a the following function:![(a, [Tree~a])](https://s0.wp.com/latex.php?latex=%28a%2C+%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002) . We use
. We use 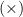 to define that two things occurs in parallel, like tuples do, so we can redefine it:
to define that two things occurs in parallel, like tuples do, so we can redefine it: ![(a \times~[Tree~a])](https://s0.wp.com/latex.php?latex=%28a+%5Ctimes%7E%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
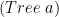 is isomorphic to
is isomorphic to ![(Tree~a) \cong~(a \times~[Tree~a])](https://s0.wp.com/latex.php?latex=%28Tree%7Ea%29+%5Ccong%7E%28a+%5Ctimes%7E%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002) .
. ,
, 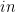 ,
,  ,
, 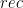 functions.
functions.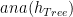 is the anamorphism of
is the anamorphism of 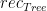 to say that function
to say that function  using the composition of
using the composition of 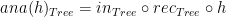
 , and that function is over
, and that function is over 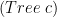 . Maybe this isn’t clear yet, let’s start with function
. Maybe this isn’t clear yet, let’s start with function  is responsible to create the isomorphism between
is responsible to create the isomorphism between 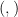 . So, type
. So, type  and
and ![D \sim c \times~[Tree~c]](https://s0.wp.com/latex.php?latex=D+%5Csim+c+%5Ctimes%7E%5BTree%7Ec%5D&bg=ffffff&fg=000000&s=0&c=20201002) . So now our graphic is:
. So now our graphic is: ) with
) with  , and
, and  became more restrict, and unify with
became more restrict, and unify with 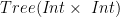 . A consequence of changing the co-domain of
. A consequence of changing the co-domain of ![(Int \times~Int) \times~[Tree (Int \times~Int)]](https://s0.wp.com/latex.php?latex=%28Int+%5Ctimes%7EInt%29+%5Ctimes%7E%5BTree+%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . We represent
. We represent ![[( h )]](https://s0.wp.com/latex.php?latex=%5B%28+h+%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Now we can be more specific with our graphic:
. Now we can be more specific with our graphic:![(Int \times~Int) \times~[Tree~(Int \times~Int)]](https://s0.wp.com/latex.php?latex=%28Int+%5Ctimes%7EInt%29+%5Ctimes%7E%5BTree%7E%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Probably the best is to pass the first part of the tuple (part with type
. Probably the best is to pass the first part of the tuple (part with type 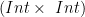 ) and the rest (part with type
) and the rest (part with type ![[Tree~(Int \times~Int)]](https://s0.wp.com/latex.php?latex=%5BTree%7E%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) ) is just a
) is just a  of the function
of the function ![[(h)]_{Tree}](https://s0.wp.com/latex.php?latex=%5B%28h%29%5D_%7BTree%7D&bg=ffffff&fg=000000&s=0&c=20201002) . So, now our graphic is:
. So, now our graphic is:![map~[(h)]_{Tree}](https://s0.wp.com/latex.php?latex=map%7E%5B%28h%29%5D_%7BTree%7D&bg=ffffff&fg=000000&s=0&c=20201002) :
:![map~[(h)]_{Tree}~:~[(Int \times~Int)] \rightarrow~[Tree(Int \times~Int)]](https://s0.wp.com/latex.php?latex=map%7E%5B%28h%29%5D_%7BTree%7D%7E%3A%7E%5B%28Int+%5Ctimes%7EInt%29%5D+%5Crightarrow%7E%5BTree%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
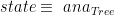 where
where 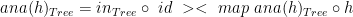
![[32]](https://s0.wp.com/latex.php?latex=%5B32%5D&bg=ffffff&fg=000000&s=0&c=20201002) means that you have a sequence of 32-bit size. All the types in Cryptol are size oriented. The unit is the
means that you have a sequence of 32-bit size. All the types in Cryptol are size oriented. The unit is the  , that you can use to represent
, that you can use to represent  , and we write:
, and we write: ![[inf]](https://s0.wp.com/latex.php?latex=%5Binf%5D&bg=ffffff&fg=000000&s=0&c=20201002) to represent that.
to represent that.![[1~..]](https://s0.wp.com/latex.php?latex=%5B1%7E..%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Cryptol will infer this sequence as type
. Cryptol will infer this sequence as type![[1~..]~:~[inf][1]](https://s0.wp.com/latex.php?latex=%5B1%7E..%5D%7E%3A%7E%5Binf%5D%5B1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![[100~..]](https://s0.wp.com/latex.php?latex=%5B100%7E..%5D&bg=ffffff&fg=000000&s=0&c=20201002) as:
as:![[100~..]~:~[inf][7]](https://s0.wp.com/latex.php?latex=%5B100%7E..%5D%7E%3A%7E%5Binf%5D%5B7%5D&bg=ffffff&fg=000000&s=0&c=20201002)
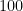 . But if you need more, you can force the type of your function.
. But if you need more, you can force the type of your function.![f~:~[a]b~\rightarrow~[a]b](https://s0.wp.com/latex.php?latex=f%7E%3A%7E%5Ba%5Db%7E%5Crightarrow%7E%5Ba%5Db&bg=ffffff&fg=000000&s=0&c=20201002)
![f~:~[a][b]c](https://s0.wp.com/latex.php?latex=f%7E%3A%7E%5Ba%5D%5Bb%5Dc&bg=ffffff&fg=000000&s=0&c=20201002) meaning that
meaning that  ,
,  function have the following type in Cryptol:
function have the following type in Cryptol:![tail~:~\{a~b\}~[a+1]b~\rightarrow~[a]b](https://s0.wp.com/latex.php?latex=tail%7E%3A%7E%5C%7Ba%7Eb%5C%7D%7E%5Ba%2B1%5Db%7E%5Crightarrow%7E%5Ba%5Db&bg=ffffff&fg=000000&s=0&c=20201002)
 of type
of type ![drop~:~\{ a~b~c \}~( fin~a ,~a~\geq~0)~\Rightarrow~(a ,[ a + b ]~c )~\rightarrow~[ b ]~c](https://s0.wp.com/latex.php?latex=drop%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%28+fin%7Ea+%2C%7Ea%7E%5Cgeq%7E0%29%7E%5CRightarrow%7E%28a+%2C%5B+a+%2B+b+%5D%7Ec+%29%7E%5Crightarrow%7E%5B+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![take~:~\{ a~b~c \}~( fin~a ,~b~\geq~0)~\Rightarrow~(a ,[ a + b ]~c )~\rightarrow~[ a ]~c](https://s0.wp.com/latex.php?latex=take%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%28+fin%7Ea+%2C%7Eb%7E%5Cgeq%7E0%29%7E%5CRightarrow%7E%28a+%2C%5B+a+%2B+b+%5D%7Ec+%29%7E%5Crightarrow%7E%5B+a+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![join~:~\{ a~b~c \}~[ a ][ b ] c~\rightarrow~[ a * b ]~c](https://s0.wp.com/latex.php?latex=join%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%5B+a+%5D%5B+b+%5D+c%7E%5Crightarrow%7E%5B+a+%2A+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![split~:~\{ a~b~c \}~[ a * b ] c~\rightarrow~[ a ][ b ]~c](https://s0.wp.com/latex.php?latex=split%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%5B+a+%2A+b+%5D+c%7E%5Crightarrow%7E%5B+a+%5D%5B+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![tail~:~\{ a~b \}~[ a +1] b~\rightarrow~[ a ]~b](https://s0.wp.com/latex.php?latex=tail%7E%3A%7E%5C%7B+a%7Eb+%5C%7D%7E%5B+a+%2B1%5D+b%7E%5Crightarrow%7E%5B+a+%5D%7Eb&bg=ffffff&fg=000000&s=0&c=20201002)

 of all the fibonacci numbers, by calling the
of all the fibonacci numbers, by calling the 






