Time to talk about efficiently pathfinding and graph traversal algorithms. The first algorithm related with graphs pathfinding I learned was Dijkstra’s algorithm and I remember the feeling for learning how to find the shortest path (minimal cost to be generic) in a graph, it was amazing to me, so that I learned a few more and did a simple academic GPS core system.
Dijkstra’s algorithm is truly beautiful, but unfortunately the complexity it too high to be considered time efficient.
If you want to go from point 


So I start to find more efficient implementations for the pathfinding problem and I discover A Star.
A Star algorithm
I find this algorithm in wikipedia, and I will paste it here because there are a few things I want to explain.
function A*(start,goal)
// The set of nodes already evaluated.
closedset := the empty set
// The set of tentative nodes to be evaluated.
openset := set containing the initial node
// The map of navigated nodes.
came_from := the empty map
// Distance from start along optimal path.
g_score[start] := 0
h_score[start] := heuristic_estimate_of_distance(start, goal)
// Estimated total distance from start to goal through y.
f_score[start] := h_score[start]
while openset is not empty
x := the node in openset having the lowest f_score[] value
if x = goal
return reconstruct_path(came_from, came_from[goal])
remove x from openset
add x to closedset
foreach y in neighbor_nodes(x)
if y in closedset
continue
tentative_g_score := g_score[x] + dist_between(x,y)
if y not in openset
add y to openset
tentative_is_better := true
elseif tentative_g_score < g_score[y]
tentative_is_better := true
else
tentative_is_better := false
if tentative_is_better = true
came_from[y] := x
g_score[y] := tentative_g_score
h_score[y] := heuristic_estimate_of_distance(y, goal)
f_score[y] := g_score[y] + h_score[y]
return failure
function reconstruct_path(came_from, current_node)
if came_from[current_node] is set
p = reconstruct_path(came_from, came_from[current_node])
return (p + current_node)
else
return current_node
If you are familiarized with Dijkstra’s algorithm you probably noticed a lot of coincidences in the algorithm. You are right!
So, we have some structures to use: the 



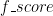


A good thing about A Star is the nodes it needs to search until find the Best-First-Search path:

Seems good right? All the juice of this algorithms lies on the heuristic function, I like the result of the Manhattan distance, but you can read this blog post and find out more about this subject.
Basically this heuristic is empirical knowledge, this particular Manhattan distance calculates the distance from point
I tried to use it in a Geometric graph and it worked fine too!
Point of view
I’m particularly interested in optimizing this algorithm as much as possible and will be doing that using C++.
So, I spend 30 minutes observing the code and I was already very familiarized with Dijkstra’s. I think as a Software Engineer you have to find good algorithms to your problem, deeply understand them, but your job is not done after that! After find a good solution and understand it to the point you are able to explain it to a non-CS person you have to *observe* the code, talk with it and, believe me, don’t make the literal implementation of it, It will be slow, or at least it probably could be more efficient!
So, let’s forget about the problem this algorithm solves and try to identify inefficient chunks in the algorithm. The first thing that cames to my mind is: we need to have a bunch of structures to keep a lot of node related information, a lot of vectors, sets and so.
So, let’s identify what I mean by that:
function A*(start,goal)
...
while openset is not empty
...
x := the node in openset having the lowest f_score[] value
...
foreach y in neighbor_nodes(x)
...
g_score[y] := tentative_g_score
h_score[y] := heuristic_estimate_of_distance(y, goal)
f_score[y] := g_score[y] + h_score[y]
With this chunk of code I want to highlight that we are iterating throw all neighbors for each 

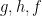

The first thing hitting me is, I can make 
So, I start to put all this information in the nodes side and keep only track of the locally created minHeap. This is the result:
LinkedList<Edge*> AStar::findPath(Node* start, Node* goal) {
LinkedList<Edge*> ret;
MinHeap<Node*, Comparator> openSet;
bool tentative_is_better = false;
float h = heuristic(start,goal);
start->setStatus(NODE_OPEN);
start->getOrSetScore().set(NULL, h,0,h);
openSet.insert(start);
while(!openSet.isEmpty()) {
Node x = openSet.getMin();
AStarScore & xScore = x->getOrSetScore();
if(x == goal) return process(ret,x);
openSet.removeMin();
x->setStatus(NODE_CLOSE);
ArrayList<Edge> & neighbors = x->getEdges();
for(int i = 0; i < neighbors.getLength (); i++) {
Node *y = neighbors [i]->getDstNode();
AStarScore & yScore = y->getOrSetScore();
GeoNodeStatus yStatus = y->getStatus();
if(yStatus == NODE_CLOSE) {
continue;
}
float tentative_g_score = xScore.g_score + x->getEdge(y)->getCost();
if(yStatus != NODE_OPEN) {
y->setStatus(_version,GEONODE_OPEN);
tentative_is_better = true;
} else if(tentative_g_score < yScore.g_score) {
tentative_is_better = true;
} else {
tentative_is_better = false;
}
if(tentative_is_better) {
yScore.parent = x;
yScore.g_score = tentative_g_score;
yScore.h_score = heuristic(y,goal);
yScore.f_score = yScore.g_score + yScore.h_score;
openSet.insert(y);
}
}
}
return process(ret,goal);
}
Where 


One side note, A star is so close to Dijkstra, that if you make you 
Basically the ideas I want to transmit here is the A star algorithm, it implementation and (the most important one) the process of how to look to an algorithm. Summarizing I think a Software Engineer could not just implement algorithms and substitute all the words 

Acknowledgments
Images from here.






