I, Pedro Faria and Jose Pedro Silva have been working on a LALR to LL conversor. Our idea was to discover the problems involved in this type of automatic conversion.
Our main goal here was to receive an LALAR(1) grammar and produce an LL(k) one. As a test case we receive an Yacc and produce ANTLR.
For the purpose of testing we used the LogoLISS grammar, a language inspired in LOGO programming language and developed in my university to school grammars and program transformation.
The main Yacc grammar was kind of a big one, here it is:
Liss : PROGRAM IDENT '{' Body '}'
;
Body : DECLARATIONS Declarations
STATEMENTS Statements
;
Declarations : Declaration
| Declarations Declaration
;
Declaration : Variable_Declaration
;
Variable_Declaration : Vars SETA Type ';'
;
Vars : Var
| Vars ',' Var
;
Var : IDENT Value_Var
;
Value_Var :
| '=' Inic_Var
;
Type : INTEGER
| BOOLEAN
| ARRAY SIZE NUM
;
Inic_Var : Constant
| Array_Definition
;
Constant : '(' Sign NUM ')'
| TRUE
| FALSE
;
Sign :
| '+'
| '-'
;
Array_Definition : '[' Array_Initialization ']'
;
Array_Initialization : Elem
| Array_Initialization ',' Elem
;
Elem : Sign NUM
;
Statements : Statement
| Statements Statement
;
Statement : Turtle_Commands
| Assignment
| Conditional_Statement
| Iterative_Statement
;
Turtle_Commands : Step
| Rotate
| Mode
| Dialogue
| Location
;
Step : FORWARD Expression
| BACKWARD Expression
;
Rotate : RRIGHT
| RLEFT
;
Mode : PEN UP
| PEN DOWN
;
Dialogue : Say_Statement
| Ask_Statement
;
Location : GOTO NUM ',' NUM
| WHERE '?'
;
Assignment : Variable '=' Expression
;
Variable : IDENT Array_Acess
;
Array_Acess :
| '[' Single_Expression ']'
;
Expression : Single_Expression
| Expression Rel_Op Single_Expression
;
Single_Expression : Term
| Single_Expression Add_Op Term
;
Term : Factor
| Term Mul_Op Factor
;
Factor : Constant
| Variable
| SuccOrPred
| '(' '!' Expression ')'
| '(' '+' Expression ')'
| '(' '-' Expression ')'
| '(' Expression ')'
;
Add_Op : '+'
| '-'
| OU
;
Mul_Op : '*'
| '/'
| E
| MULTMULT
;
Rel_Op : IGUAL
| DIF
| '<' | '>'
| MENORIGUAL
| MAIORIGUAL
| IN
;
SuccOrPred : SuccPred IDENT
;
SuccPred : SUCC
| PRED
;
Say_Statement : SAY '(' Expression ')'
;
Ask_Statement : ASK '(' STRING ',' Variable ')'
;
Conditional_Statement : IfThenElse_Stat
;
Iterative_Statement : While_Stat
;
IfThenElse_Stat : IF Expression THEN '{' Statements '}' Else_Expression
;
Else_Expression :
| ELSE '{' Statements '}'
;
While_Stat : WHILE '(' Expression ')' '{' Statements '}'
;
This is a toy grammar to help students to understand and get a deep knoledge of some fundamental types of productions in grammars.
The kind of texts this grammar is able to analyse are:
PROGRAM logolissExample {
DECLARATIONS
x = (100) , y -> Integer ;
z -> Boolean ;
w = TRUE -> Boolean ;
STATEMENTS
FORWARD x
RRIGHT
y = (100)
FORWARD e
RRIGHT
x = x - (100) + (20)
FORWARD x + (100)
RRIGHT
FORWARD (100)
}
Rules
After some time thinking about this problem we tried to solve the left recursion problem. ANTLR does not know how to handle with left recursion, so we must use the EBNF support to translate this productions.
Grammar rules in BNF provide for concatenation and choice but no specific operation equivalent to the * of regular expressions are provided. In Yacc the only way we get repetition is using the following pattern:
A : A a | a ;
We call this kind of rules a left recursive rule.
So, we discover this two generalized rules to remove left recursion in Yacc grammars (click on the image to expand):

Implementation
So, we start right over the implementation of the conversor. We used Yapp because lately we have been using a lot of Perl, so we are want to get deeper into Perl packages.
We start to implement the definition of a Yacc grammar in Yapp:
productions : production
| productions production
;
production : nonTerminal ':' derivs ';'
;
derivs : nts
| derivs '|' nts
|
;
nts : nt
| nts nt
;
nt : terminal
| nonTerminal
| sep
;
terminal : STRING_TERMINAL
;
nonTerminal : STRING_NON_TERMINAL
;
sep : SEPARATOR
;
And we move along to represent this information in a structure. We chose an peculiar structure to help us processing it.
This is the structure defined as Haskell types:
type Grammar = [Production] type Production = HashTable ProductionName [Derivation] type Derivation = [HashTable NTS Type] type Type = String type NTS = String
Easy to find stuff, easy to implement in Perl 🙂
So, this is our Yapp grammar again but this time with semantic actions:
productions : production { return $_[1]; }
| productions production {
push @{$_[1]},@{$_[2]};
return $_[1];
}
;
production : nonTerminal ':' derivs ';' { return [ { $_[1] => $_[3] } ]; }
;
derivs : nts { return [$_[1]]; }
| derivs '|' nts {
push @{$_[1]},$_[3];
return $_[1];
}
| { return [[ { 'epsilon' => 'epsilon' } ]]; }
;
nts : nt { return $_[1]; }
| nts nt {
push @{$_[1]},@{$_[2]};
return $_[1];
}
;
nt : terminal {
return [ { $_[1] => 'terminal' } ];
}
| nonTerminal {
return [ { $_[1] => 'nonTerminal' } ];
}
| sep {
return [ { $_[1] => 'sep' } ];
}
;
terminal : STRING_TERMINAL {
return $_[1];
}
;
nonTerminal : STRING_NON_TERMINAL {
return $_[1];
}
;
sep : SEPARATOR {
return $_[1];
}
;
After we had this structure filled in we applied the two rules shown before and we get rid of left recursion for good.
So, after we process the following grammars with our transformer:
a : a B C
| //nothing
;
expr : expr "+" expr
| expr "-" expr
| expr "*" expr
;
We get:
a : (B C)*
;
expr : ( "+" expr)+
| ( "-" expr)+
| ( "*" expr)+
;
You can see all the code produced (including makefiles) in my github repo.
Other rules
We have noticed that only removing the left recursion makes this grammar work in ANTLR.
We are aware that to fully convert an LALR grammar to LL we need one other step: Left Factoring.
Because our LL system is 
Examples like this are not a problem for our destination system.
expr: T A B
| T C D
;
However if our destination grammar was LL(1) we needed to convert this to it’s EBNF form.
Lexer
We also translated the Lex used in flex to ANTLR. The main problem here is that we used only matching functions in Perl and we do not used any grammar for this effect.
The main problem is that the regular expressions in flex are different to regexps in ANTLR.
You can see the Perl code for yourself here.
But you if you want to do a translation from flex to ANTLR better you define a flex grammar.
 variable for nothing, just have declared it. And the result is:
variable for nothing, just have declared it. And the result is: element cross the array
element cross the array  times and for each element we compare with
times and for each element we compare with  must be greater than zero, and all the positions in that vector exists, so in Frama-C we use the
must be greater than zero, and all the positions in that vector exists, so in Frama-C we use the  , where
, where  are indexes of the
are indexes of the 

 , our code will be proved and its wrong!
, our code will be proved and its wrong!
 . If your code returns
. If your code returns  (we miss the repeated
(we miss the repeated  ) the code will be proved.
) the code will be proved.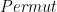 predicate and prove for the
predicate and prove for the 

 and if we want to refer to the moment after the call we heave the
and if we want to refer to the moment after the call we heave the  keyword, remember we are at the post condition, so this wil be executed in the end (so
keyword, remember we are at the post condition, so this wil be executed in the end (so  predicate. Predicates receive a state
predicate. Predicates receive a state  and the parameters (just like a function) and they return bool values (true or false). Inside we use regular ACSL notation. Here I define that for an array to be sorted each element must be less or equal to the next one.
and the parameters (just like a function) and they return bool values (true or false). Inside we use regular ACSL notation. Here I define that for an array to be sorted each element must be less or equal to the next one.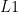 and
and  and the array
and the array  and the range where we want to permute.
and the range where we want to permute. . So basically here we say that a permutation is a set of successive swaps.
. So basically here we say that a permutation is a set of successive swaps.![[32]](https://s0.wp.com/latex.php?latex=%5B32%5D&bg=ffffff&fg=000000&s=0&c=20201002) means that you have a sequence of 32-bit size. All the types in Cryptol are size oriented. The unit is the
means that you have a sequence of 32-bit size. All the types in Cryptol are size oriented. The unit is the  , that you can use to represent
, that you can use to represent 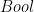 . To represent a infinite sequence we use the reserved word
. To represent a infinite sequence we use the reserved word  , and we write:
, and we write: ![[inf]](https://s0.wp.com/latex.php?latex=%5Binf%5D&bg=ffffff&fg=000000&s=0&c=20201002) to represent that.
to represent that.![[1~..]](https://s0.wp.com/latex.php?latex=%5B1%7E..%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Cryptol will infer this sequence as type
. Cryptol will infer this sequence as type![[1~..]~:~[inf][1]](https://s0.wp.com/latex.php?latex=%5B1%7E..%5D%7E%3A%7E%5Binf%5D%5B1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![[100~..]](https://s0.wp.com/latex.php?latex=%5B100%7E..%5D&bg=ffffff&fg=000000&s=0&c=20201002) as:
as:![[100~..]~:~[inf][7]](https://s0.wp.com/latex.php?latex=%5B100%7E..%5D%7E%3A%7E%5Binf%5D%5B7%5D&bg=ffffff&fg=000000&s=0&c=20201002)
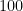 . But if you need more, you can force the type of your function.
. But if you need more, you can force the type of your function.![f~:~[a]b~\rightarrow~[a]b](https://s0.wp.com/latex.php?latex=f%7E%3A%7E%5Ba%5Db%7E%5Crightarrow%7E%5Ba%5Db&bg=ffffff&fg=000000&s=0&c=20201002)
 have polymorphism over
have polymorphism over ![f~:~[a][b]c](https://s0.wp.com/latex.php?latex=f%7E%3A%7E%5Ba%5D%5Bb%5Dc&bg=ffffff&fg=000000&s=0&c=20201002) meaning that
meaning that  ,
,  function have the following type in Cryptol:
function have the following type in Cryptol:![tail~:~\{a~b\}~[a+1]b~\rightarrow~[a]b](https://s0.wp.com/latex.php?latex=tail%7E%3A%7E%5C%7Ba%7Eb%5C%7D%7E%5Ba%2B1%5Db%7E%5Crightarrow%7E%5Ba%5Db&bg=ffffff&fg=000000&s=0&c=20201002)
 of type
of type ![drop~:~\{ a~b~c \}~( fin~a ,~a~\geq~0)~\Rightarrow~(a ,[ a + b ]~c )~\rightarrow~[ b ]~c](https://s0.wp.com/latex.php?latex=drop%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%28+fin%7Ea+%2C%7Ea%7E%5Cgeq%7E0%29%7E%5CRightarrow%7E%28a+%2C%5B+a+%2B+b+%5D%7Ec+%29%7E%5Crightarrow%7E%5B+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![take~:~\{ a~b~c \}~( fin~a ,~b~\geq~0)~\Rightarrow~(a ,[ a + b ]~c )~\rightarrow~[ a ]~c](https://s0.wp.com/latex.php?latex=take%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%28+fin%7Ea+%2C%7Eb%7E%5Cgeq%7E0%29%7E%5CRightarrow%7E%28a+%2C%5B+a+%2B+b+%5D%7Ec+%29%7E%5Crightarrow%7E%5B+a+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![join~:~\{ a~b~c \}~[ a ][ b ] c~\rightarrow~[ a * b ]~c](https://s0.wp.com/latex.php?latex=join%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%5B+a+%5D%5B+b+%5D+c%7E%5Crightarrow%7E%5B+a+%2A+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![split~:~\{ a~b~c \}~[ a * b ] c~\rightarrow~[ a ][ b ]~c](https://s0.wp.com/latex.php?latex=split%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%5B+a+%2A+b+%5D+c%7E%5Crightarrow%7E%5B+a+%5D%5B+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![tail~:~\{ a~b \}~[ a +1] b~\rightarrow~[ a ]~b](https://s0.wp.com/latex.php?latex=tail%7E%3A%7E%5C%7B+a%7Eb+%5C%7D%7E%5B+a+%2B1%5D+b%7E%5Crightarrow%7E%5B+a+%5D%7Eb&bg=ffffff&fg=000000&s=0&c=20201002)

 of all the fibonacci numbers, by calling the
of all the fibonacci numbers, by calling the 












