Intro
Like I promise I will talk about point-free over non recursive functions.
Point-free style is used to demonstrate propriety over programs easily than pointwise.
Because we didn’t have variables in functions, we can compose a lot of small functions with each other using some combinators.
Those combinators have some rules associate with them that tell us when to use some combinator.Also because I think that’s the easy way to learn point-free programming style. I will talk about that style over non recursive functions.
Because of the length of what I intend to explain I will talk about these theme in three more post’s. Consider this part I.
In the following parts I will talk about:
- Co-Products (Part II)
- Constants and conditionals (Part III)
- Pointfree – Pointwise conversion & Program calculation (Part IV)
At the time I finish the other posts I will put their link here.
Part I
In this post I will talk about products of functions and some of their rules.
I will use 
I will also use Commutative diagrams to explain the rules, Because I think that is the easy way to get it.
Combinators
The combinator 



In fact
Another very important function is the 







With just those laws we are ready to demonstrate programs, like:
Let A, B, C, D be Types and f :: A -> B, g :: B -> C and h :: C -> D
let’s prove that

To demonstrate this equality we pick one of the sides of the equation, and with 

In this case, we can do:
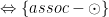





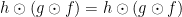

1) In fact as a convenience we can take off the brakets in a sequence os compositions. And so is pointless the use of
2) We can also use more than one rule per line.
So, the previous demonstation becames:




split combinator
In any programming language we always have two general types to aggregate data, struct’s and unions.
Now we will see two combinators that work with those data types.
The 
It definition is:



in Haskell became:
split :: (c -> a) -> (c -> b) -> c -> (a,b) split f g x = (f x, g x)
This combinator allow, as well, combine functions with the same domain.
With the functions ‘fst’ and ‘snd’ we can access the content of a tuple.
fst (a,b) = a snd (a,b) = b
Let A, B, C, D be Types and f : A -> B, g : A -> C and we want the function split : A -> B x C
Like diagram is commutative we can infer two rules:





Now, if type A = B x C, we will have

To have a commutative diagram 

And we can infer the rule:


Let A, B, C, E be Types and h : A -> B, f : B -> C and g : B -> E.


Example – isomorphism demonstration
As example we can demonstrate isomorphisms.
Here is a brief description:
To prove the isomorphism
we have to find two functions:
and
such that

To do that we can use the diagrams or doscover the pointwise version and them converte to point-free, I will show later on the last techique.
Now we gonna use the diagrams to show the isomorphism 
Discovering g:
So, the definition of the function h is:


Discovering

So, the definition of the function 


And we conclude 
 combinator
combinator
When we want to defin a function that takes a product and goes to a product we may use the function



in Haskell became:
infixr 5 > b) -> (c -> d) -> (a, c) -> (b, d) (f >< g) x = split (f . fst) (g . snd)
here is the diagram of it definition:
The folowing diagram,
coud be simplified into this one:
And so, we find another rule:


The folowing diagram,



Notes
The 
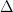
So,

Aknowledgements
I would like to thank dysfunctor to the corrections made to this post.






