Currently I am doing research at the University of Minho in the group of distributed systems, with duration of one year. My job is to find a way to identify specific links between a user and a distributed system. The general idea is to draw a map of services in a distributed system. This post only refers to the first milestone.
The proposal was to make such a system using Snort.
Snort
![]() Snort is a Network intrusion detection system, that means with Snort you can detect malicious activity in your network. We can detect many types of network attacks. We can identify DoS, DDoS attacks, port scans, cracking attempts, and much more.
Snort is a Network intrusion detection system, that means with Snort you can detect malicious activity in your network. We can detect many types of network attacks. We can identify DoS, DDoS attacks, port scans, cracking attempts, and much more.
Snort can operate in two different ways. We can set up Snort to run in passive mode, putting it to listen in promiscuous mode. That is, because Ethernet network switches send traffic to all computers connected to itself, we get traffic addressed to other machines on the network. To do this we only need to connect to the network and turn Snort on in our machine, no one knows that we are recording every traffic (including traffic destined for other computers).
Snort may also run in active mode. This “active” is not able to modify the data channel, but to be able to be installed in a network, a router for example and reap more information than in passive mode. Thus it makes sense to use the capacity of rules that Snort supports, to filter the traffic that it read.
To do this, Snort capture all packets that pass the network and interprets each. As the rules we have defined Snort tries to find these patterns in each packet, or each set of packets and take certain actions for each of them.
For example, if a large number of TCP requests reach a particular host, to a large number of ports in a short space of time we probably are the target of a port scan. NIDS like Snort know how to find these patterns and alerting the network administrator.
Objective
Our aim was to use Snort to capture all traffic into passive mode.
root@pig:# snort -u snort -g snort -D -d -l /var/log/snort -c /etcsnort/snort.debian.conf -i eth0
We are saving the logs in binary (tcpdump format), for that I use the “-d -l /dir/” flags. I prefer to save all the packets into binary because is more easier to parse, than the structure of files and directories that Snort creates by default.
I started by trying to use some language that advised me to try to do the parsing of the file created by snort. Initially started to use python, but only find a tcpdump parser and could not get more than one file translated in tcpdump to hexadecimal.
After that I tried to use Haskell and I was amazed!
Haskell and packet parsing
House is a Haskell Operative System done by The Programatica Project.
This is a system than can serve as a platform for exploring various ideas relating to low-level and system-level programming in a high-level functional language.
And indeed helped me a lot in doing my job. This project have already done a lot of parsers for network packets. It implements the Ethernet, IPv4, IPv6, TCP, UDP, ICMP, ARP and I think is all.
The libpcap (tcpdump parser) is already implemented in Haskell too, so is very simple to parse a complete packet:
getPacket :: [Word8] -> InPacket getPacket bytes = toInPack $ listArray (0,Prelude.length bytes-1) $ bytes -- Ethernet | IP | TCP | X getPacketTCP :: [Word8] -> Maybe (NE.Packet (NI4.Packet (NT.Packet InPacket))) getPacketTCP bytes = doParse $ getPacket bytes :: Maybe (NE.Packet (NI4.Packet (NT.Packet InPacket)))
As you can see is too easy to have a compete structure of a packet parsed with this libraries. The problem is that they don’t have already implemented a application packet parser. So, according to that image:

This is the level of depth we can go with this libraries. What is very good, but not perfect for me :S
My supervisor told me to start searching a new tool to do this job. I was sad because I could not do everything in Haskell. But it is already promised that I will continue this project in Haskell. You can see the git repo here.
I find tshark, a great tool to dissect and analyze data inside tcpdump files.
The power of tshark
tshark is the terminal based Wireshark, with it we can do everything we do with wireshark.
Show all communications with the IP 192.168.74.242
root@pig:# tshark -R "ip.addr == 192.168.74.242" -r snort.log
... 7750 6079.816123 193.136.19.96 -> 192.168.74.242 SSHv2 Client: Key Exchange Init 7751 6079.816151 192.168.74.242 -> 193.136.19.96 TCP ssh > 51919 [ACK] Seq=37 Ack=825 Win=7424 Len=0 TSV=131877388 TSER=1789588 7752 6079.816528 192.168.74.242 -> 193.136.19.96 SSHv2 Server: Key Exchange Init 7753 6079.817450 193.136.19.96 -> 192.168.74.242 TCP 51919 > ssh [ACK] Seq=825 Ack=741 Win=7264 Len=0 TSV=1789588 TSER=131877389 7754 6079.817649 193.136.19.96 -> 192.168.74.242 SSHv2 Client: Diffie-Hellman GEX Request 7755 6079.820784 192.168.74.242 -> 193.136.19.96 SSHv2 Server: Diffie-Hellman Key Exchange Reply 7756 6079.829495 193.136.19.96 -> 192.168.74.242 SSHv2 Client: Diffie-Hellman GEX Init 7757 6079.857490 192.168.74.242 -> 193.136.19.96 SSHv2 Server: Diffie-Hellman GEX Reply 7758 6079.884000 193.136.19.96 -> 192.168.74.242 SSHv2 Client: New Keys 7759 6079.922576 192.168.74.242 -> 193.136.19.96 TCP ssh > 51919 [ACK] Seq=1613 Ack=1009 Win=8960 Len=0 TSV=131877415 TSER=1789605 ...
Show with a triple: (time, code http, http content size), separated by ‘,’ and between quotation marks.
root@pig:# tshark -r snort.log -R http.response -T fields -E header=y -E separator=',' -E quote=d -e frame.time_relative -e http.response.code -e http.content_length
... "128.341166000","200","165504" "128.580181000","200","75332" "128.711618000","200","1202" "149.575548000","206","1" "149.719938000","304", "149.882290000","404","338" "150.026474000","404","341" "150.026686000","404","342" "150.170295000","304", "150.313576000","304", "150.456650000","304", ...
Show a tuple of arity 4 with: (time, source ip, destination ip, tcp packet size).
root@pig:# tshark -r snort.log -R "tcp.len>0" -T fields -e frame.time_relative -e ip.src -e ip.dst -e tcp.len
... 551.751252000 193.136.19.96 192.168.74.242 48 551.751377000 192.168.74.242 193.136.19.96 144 551.961545000 193.136.19.96 192.168.74.242 48 551.961715000 192.168.74.242 193.136.19.96 208 552.682260000 193.136.19.96 192.168.74.242 48 552.683955000 192.168.74.242 193.136.19.96 1448 552.683961000 192.168.74.242 193.136.19.96 1448 552.683967000 192.168.74.242 193.136.19.96 512 555.156301000 193.136.19.96 192.168.74.242 48 555.158474000 192.168.74.242 193.136.19.96 1448 555.158481000 192.168.74.242 193.136.19.96 1400 556.021205000 193.136.19.96 192.168.74.242 48 556.021405000 192.168.74.242 193.136.19.96 160 558.874202000 193.136.19.96 192.168.74.242 48 558.876027000 192.168.74.242 193.136.19.96 1448 ...
Show with a triple: (source ip, destination ip, port of destination ip).
root@pig:# tshark -r snort.log -Tfields -e ip.src -e ip.dst -e tcp.dstport
... 192.168.74.242 193.136.19.96 37602 192.168.74.242 193.136.19.96 37602 193.136.19.96 192.168.74.242 22 192.168.74.242 193.136.19.96 37602 193.136.19.96 192.168.74.242 22 193.136.19.96 192.168.74.242 22 192.168.74.242 193.136.19.96 37602 192.168.74.242 193.136.19.96 37602 192.168.74.242 193.136.19.96 37602 193.136.19.96 192.168.74.242 22 193.136.19.96 192.168.74.242 22 193.136.19.96 192.168.74.242 22 193.136.19.96 192.168.74.242 22 192.168.74.242 193.136.19.96 37602 192.168.74.242 193.136.19.96 37602 ...
Statistics
Hierarchy of protocols
root@pig:# tshark -r snort.log -q -z io,phs
frame frames:7780 bytes:1111485
eth frames:7780 bytes:1111485
ip frames:3992 bytes:848025
tcp frames:3908 bytes:830990
ssh frames:2153 bytes:456686
http frames:55 bytes:19029
http frames:5 bytes:3559
http frames:3 bytes:2781
http frames:2 bytes:2234
http frames:2 bytes:2234
data-text-lines frames:10 bytes:5356
tcp.segments frames:3 bytes:1117
http frames:3 bytes:1117
media frames:3 bytes:1117
udp frames:84 bytes:17035
nbdgm frames:50 bytes:12525
smb frames:50 bytes:12525
mailslot frames:50 bytes:12525
browser frames:50 bytes:12525
dns frames:34 bytes:4510
llc frames:3142 bytes:224934
stp frames:3040 bytes:182400
cdp frames:102 bytes:42534
loop frames:608 bytes:36480
data frames:608 bytes:36480
arp frames:38 bytes:2046
Conversations
We use: -z conv,TYPE,FILTER
TYPE could be:
- eth,
- tr,
- fc,
- fddi,
- ip,
- ipx,
- tcp,
- udp
And the filters are used to restrict the statistics.
root@pig:# tshark -r snort.log -q -z conv,ip,tcp.port==80
================================================================================
IPv4 Conversations
Filter:tcp.port==80
| | | Total |
|Frames Bytes | |Frames Bytes | |Frames Bytes |
193.136.19.148 192.168.74.242 141 13091 202 259651 343 272742
192.168.74.242 128.31.0.36 22 6858 28 4784 50 11642
================================================================================
IO
We use: -z io,stat,INT,FILTER,…,FILTER
root@pig:# tshark -r snort.log -q -z io,stat,300,'not (tcp.port=22)'
===================================================================
IO Statistics
Interval: 300.000 secs
Column #0:
| Column #0
Time |frames| bytes
000.000-300.000 2161 543979
300.000-600.000 1671 264877
600.000-900.000 508 46224
900.000-1200.000 185 12885
1200.000-1500.000 201 14607
1500.000-1800.000 187 13386
1800.000-2100.000 189 13887
2100.000-2400.000 187 13386
2400.000-2700.000 189 13887
2700.000-3000.000 187 13386
3000.000-3300.000 185 12885
3300.000-3600.000 189 13887
3600.000-3900.000 210 15546
3900.000-4200.000 189 13887
4200.000-4500.000 187 13386
4500.000-4800.000 185 12885
4800.000-5100.000 189 13887
===================================================================
Conclusion
With tshark we could do everything we want to know what is inside a network packet. The trick is to understand the statistics that tshark generate, and know how to ask it.
Now my work will get a machine to run Snort in an active mode and begin to understand how to use Snort to do all this work of collecting information.
If you feel interested and understand Portuguese, see the presentation:
![[32]](https://s0.wp.com/latex.php?latex=%5B32%5D&bg=ffffff&fg=000000&s=0&c=20201002) means that you have a sequence of 32-bit size. All the types in Cryptol are size oriented. The unit is the
means that you have a sequence of 32-bit size. All the types in Cryptol are size oriented. The unit is the  , that you can use to represent
, that you can use to represent 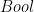 . To represent a infinite sequence we use the reserved word
. To represent a infinite sequence we use the reserved word  , and we write:
, and we write: ![[inf]](https://s0.wp.com/latex.php?latex=%5Binf%5D&bg=ffffff&fg=000000&s=0&c=20201002) to represent that.
to represent that.![[1~..]](https://s0.wp.com/latex.php?latex=%5B1%7E..%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Cryptol will infer this sequence as type
. Cryptol will infer this sequence as type![[1~..]~:~[inf][1]](https://s0.wp.com/latex.php?latex=%5B1%7E..%5D%7E%3A%7E%5Binf%5D%5B1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![[100~..]](https://s0.wp.com/latex.php?latex=%5B100%7E..%5D&bg=ffffff&fg=000000&s=0&c=20201002) as:
as:![[100~..]~:~[inf][7]](https://s0.wp.com/latex.php?latex=%5B100%7E..%5D%7E%3A%7E%5Binf%5D%5B7%5D&bg=ffffff&fg=000000&s=0&c=20201002)
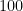 . But if you need more, you can force the type of your function.
. But if you need more, you can force the type of your function.![f~:~[a]b~\rightarrow~[a]b](https://s0.wp.com/latex.php?latex=f%7E%3A%7E%5Ba%5Db%7E%5Crightarrow%7E%5Ba%5Db&bg=ffffff&fg=000000&s=0&c=20201002)
 have polymorphism over
have polymorphism over  , because we say that it domain is one sequence of size
, because we say that it domain is one sequence of size  of type
of type ![f~:~[a][b]c](https://s0.wp.com/latex.php?latex=f%7E%3A%7E%5Ba%5D%5Bb%5Dc&bg=ffffff&fg=000000&s=0&c=20201002) meaning that
meaning that  ,
,  function have the following type in Cryptol:
function have the following type in Cryptol:![tail~:~\{a~b\}~[a+1]b~\rightarrow~[a]b](https://s0.wp.com/latex.php?latex=tail%7E%3A%7E%5C%7Ba%7Eb%5C%7D%7E%5Ba%2B1%5Db%7E%5Crightarrow%7E%5Ba%5Db&bg=ffffff&fg=000000&s=0&c=20201002)
 of type
of type ![drop~:~\{ a~b~c \}~( fin~a ,~a~\geq~0)~\Rightarrow~(a ,[ a + b ]~c )~\rightarrow~[ b ]~c](https://s0.wp.com/latex.php?latex=drop%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%28+fin%7Ea+%2C%7Ea%7E%5Cgeq%7E0%29%7E%5CRightarrow%7E%28a+%2C%5B+a+%2B+b+%5D%7Ec+%29%7E%5Crightarrow%7E%5B+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![take~:~\{ a~b~c \}~( fin~a ,~b~\geq~0)~\Rightarrow~(a ,[ a + b ]~c )~\rightarrow~[ a ]~c](https://s0.wp.com/latex.php?latex=take%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%28+fin%7Ea+%2C%7Eb%7E%5Cgeq%7E0%29%7E%5CRightarrow%7E%28a+%2C%5B+a+%2B+b+%5D%7Ec+%29%7E%5Crightarrow%7E%5B+a+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![join~:~\{ a~b~c \}~[ a ][ b ] c~\rightarrow~[ a * b ]~c](https://s0.wp.com/latex.php?latex=join%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%5B+a+%5D%5B+b+%5D+c%7E%5Crightarrow%7E%5B+a+%2A+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![split~:~\{ a~b~c \}~[ a * b ] c~\rightarrow~[ a ][ b ]~c](https://s0.wp.com/latex.php?latex=split%7E%3A%7E%5C%7B+a%7Eb%7Ec+%5C%7D%7E%5B+a+%2A+b+%5D+c%7E%5Crightarrow%7E%5B+a+%5D%5B+b+%5D%7Ec&bg=ffffff&fg=000000&s=0&c=20201002)
![tail~:~\{ a~b \}~[ a +1] b~\rightarrow~[ a ]~b](https://s0.wp.com/latex.php?latex=tail%7E%3A%7E%5C%7B+a%7Eb+%5C%7D%7E%5B+a+%2B1%5D+b%7E%5Crightarrow%7E%5B+a+%5D%7Eb&bg=ffffff&fg=000000&s=0&c=20201002)

 of all the fibonacci numbers, by calling the
of all the fibonacci numbers, by calling the 
















