If you lost yourself in this post, I advise you to start in catamorphisms, then anamorphisms and then hylomorphisms.
Like I said before (in those posts) when you write an hylomorphism over a particular data type, that means just that the intermediate structure is that data type.

In fact that data will never be stored into that intermediate type 


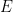
Leaf Tree’s
The data type that we going to discuss here is the 
data LTree a = Leaf a | Fork (LTree a, LTree a)
Is just like a binary tree, but the information is just in the leaf’s. Even more: a leaf tree is a tree that only have leaf’s, no information on the nodes. This is an example of a leaf tree:
To represent all the hylomorphisms over 
The example I’m going to give is making the fibonacci function using a hylomorphism over this data type. If you remember the method I used before, I’m going to start by the anamorphism ![[(h)]](https://s0.wp.com/latex.php?latex=%5B%28h%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)

As you can see I’m going to use 

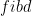
fibd n | n < 2 = i1 ()
| otherwise = i2 (n-1,n-2)
This function combined with the anamorphism, going to generate leaf tree’s with 
Then we just have to write the gen
add = either (const 1) plus
where plus = uncurry (+)
The final function, the fibonacci function is the hylomorphism of those two defined before:
fib = hyloLTree add fibd
Here is all the auxiliary functions you need to run this example:
inLTree = either Leaf Fork outLTree :: LTree a -> Either a (LTree a,LTree a) outLTree (Leaf a) = i1 a outLTree (Fork (t1,t2)) = i2 (t1,t2) cataLTree a = a . (recLTree (cataLTree a)) . outLTree anaLTree f = inLTree . (recLTree (anaLTree f) ) . f hyloLTree a c = cataLTree a . anaLTree c baseLTree g f = g -|- (f >< f) recLTree f = baseLTree id f
Lists
The lists that I’m going to talk here, are the Haskell lists, wired into the compiler, but is a definition exist, it will be:
data [a] = [ ] | a : [a]
So, our diagram to represent the hylomorphism over this data type is:
The function I’m going to define as a hylomorphism is the factorial function. So, we know that our domain and co-domain is 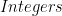
As you can see I’m going to use ![[Integer]](https://s0.wp.com/latex.php?latex=%5BInteger%5D&bg=ffffff&fg=000000&s=0&c=20201002)


mul = either (const 1) mul'
where mul' = uncurry (*)
As you can see the only thing it does is multiply all the elements of a list, and multiply by 1 when reach the ![[]](https://s0.wp.com/latex.php?latex=%5B%5D&bg=ffffff&fg=000000&s=0&c=20201002)
In the other side, the anamorphism is generating a list of all the elements, starting in
nats = (id -|- (split succ id)) . outNat
And finally we combine this together with our hylo, that defines the factorial function:
fac = hylo mul nats
Here is all the code you need to run this example:
inl = either (const []) (uncurry (:)) out [] = i1 () out (a:x) = i2(a,x) cata g = g . rec (cata g) . out ana h = inl . (rec (ana h) ) . h hylo g h = cata g . ana h rec f = id -|- id >< f
Binary Tree’s
Here, I’m going to show you the hanoi problem solved with one hylomorphism, first let’s take a look at the 
data BTree a = Empty | Node(a, (BTree a, BTree a))
So, our generic diagram representing one hylomorphism over 
There is a well-known inductive solution to the problem given by the pseudocode below. In this solution we make use of the fact that the given problem is symmetrical with respect to all three poles. Thus it is undesirable to name the individual poles. Instead we visualize the poles as being arranged in a circle; the problem is to move the tower of disks from one pole to the next pole in a specified direction around the circle. The code defines
to be a sequence of pairs
where n is the number of disks,
is a disk number and
are directions. Disks are numbered from
onwards, disk
representing a clockwise movement and
an anti-clockwise movement. The pair
excerpt from R. Backhouse, M. Fokkinga / Information Processing Letters 77 (2001) 71–76
So, here, I will have a diagram like that, 
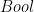


I’m going to show all the solution here, because the description of the problem is in this quote, and in the paper:
hanoi = hyloBTree f h
f = either (const []) join
where join(x,(l,r))=l++[x]++r
h(d,0) = Left ()
h(d,n+1) = Right ((n,d),((not d,n),(not d,n)))
And here it is, all the code you need to run this example:
inBTree :: Either () (b,(BTree b,BTree b)) -> BTree b inBTree = either (const Empty) Node outBTree :: BTree a -> Either () (a,(BTree a,BTree a)) outBTree Empty = Left () outBTree (Node (a,(t1,t2))) = Right(a,(t1,t2)) baseBTree f g = id -|- (f >< g)) cataBTree g = g . (recBTree (cataBTree g)) . outBTree anaBTree g = inBTree . (recBTree (anaBTree g) ) . g hyloBTree h g = cataBTree h . anaBTree g recBTree f = baseBTree id f
Outroduction
Maybe in the future I will talk more about that subject.
 , replacing that by the proper notation we have:
, replacing that by the proper notation we have: ![[|f,h|]~=~(|f|)~\circ~[(h)]](https://s0.wp.com/latex.php?latex=%5B%7Cf%2Ch%7C%5D%7E%3D%7E%28%7Cf%7C%29%7E%5Ccirc%7E%5B%28h%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 , what we are trying to say is that the intermediate structure of our combination of catamorphism and anamorphism is that data type
, what we are trying to say is that the intermediate structure of our combination of catamorphism and anamorphism is that data type  function works over lists. So the first thing to do, is draw the respective anamorphism from
function works over lists. So the first thing to do, is draw the respective anamorphism from ![[a]](https://s0.wp.com/latex.php?latex=%5Ba%5D&bg=ffffff&fg=000000&s=0&c=20201002) to
to  :
: with type:
with type:![h : [a] \rightarrow 1 + a \times [a] \times [a]](https://s0.wp.com/latex.php?latex=h+%3A+%5Ba%5D+%5Crightarrow+1+%2B+a+%5Ctimes+%5Ba%5D+%5Ctimes+%5Ba%5D&bg=ffffff&fg=000000&s=0&c=20201002) , or in Haskell
, or in Haskell ![h :: [a] \rightarrow Either () (a, ([a], [a]))](https://s0.wp.com/latex.php?latex=h+%3A%3A+%5Ba%5D+%5Crightarrow+Either+%28%29+%28a%2C+%28%5Ba%5D%2C+%5Ba%5D%29%29&bg=ffffff&fg=000000&s=0&c=20201002)
 :
: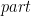 , it process all the list finding the elements that satisfy the condition
, it process all the list finding the elements that satisfy the condition  , to put them in the left side of the tuple, and the others into the right side.
, to put them in the left side of the tuple, and the others into the right side.![a + a \times [a] \times [a]](https://s0.wp.com/latex.php?latex=a+%2B+a+%5Ctimes+%5Ba%5D+%5Ctimes+%5Ba%5D&bg=ffffff&fg=000000&s=0&c=20201002) , which is very simple, as as shown by the code.
, which is very simple, as as shown by the code. :
: , i can say:
, i can say: , and composition
, and composition  functions.
functions. :
: as a the following function:
as a the following function:![(a, [Tree~a])](https://s0.wp.com/latex.php?latex=%28a%2C+%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002) . We use
. We use 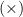 to define that two things occurs in parallel, like tuples do, so we can redefine it:
to define that two things occurs in parallel, like tuples do, so we can redefine it: ![(a \times~[Tree~a])](https://s0.wp.com/latex.php?latex=%28a+%5Ctimes%7E%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
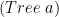 is isomorphic to
is isomorphic to ![(Tree~a) \cong~(a \times~[Tree~a])](https://s0.wp.com/latex.php?latex=%28Tree%7Ea%29+%5Ccong%7E%28a+%5Ctimes%7E%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002) .
. ,
, 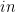 ,
,  ,
, 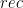 functions.
functions.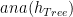 is the anamorphism of
is the anamorphism of 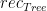 to say that function
to say that function  using the composition of
using the composition of 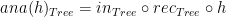
 , and that function is over
, and that function is over 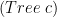 . Maybe this isn’t clear yet, let’s start with function
. Maybe this isn’t clear yet, let’s start with function  is responsible to create the isomorphism between
is responsible to create the isomorphism between 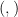 . So, type
. So, type  and
and ![D \sim c \times~[Tree~c]](https://s0.wp.com/latex.php?latex=D+%5Csim+c+%5Ctimes%7E%5BTree%7Ec%5D&bg=ffffff&fg=000000&s=0&c=20201002) . So now our graphic is:
. So now our graphic is: ) with
) with  , and
, and  became more restrict, and unify with
became more restrict, and unify with 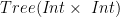 . A consequence of changing the co-domain of
. A consequence of changing the co-domain of ![(Int \times~Int) \times~[Tree (Int \times~Int)]](https://s0.wp.com/latex.php?latex=%28Int+%5Ctimes%7EInt%29+%5Ctimes%7E%5BTree+%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . We represent
. We represent ![[( h )]](https://s0.wp.com/latex.php?latex=%5B%28+h+%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Now we can be more specific with our graphic:
. Now we can be more specific with our graphic:![(Int \times~Int) \times~[Tree~(Int \times~Int)]](https://s0.wp.com/latex.php?latex=%28Int+%5Ctimes%7EInt%29+%5Ctimes%7E%5BTree%7E%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Probably the best is to pass the first part of the tuple (part with type
. Probably the best is to pass the first part of the tuple (part with type 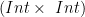 ) and the rest (part with type
) and the rest (part with type ![[Tree~(Int \times~Int)]](https://s0.wp.com/latex.php?latex=%5BTree%7E%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) ) is just a
) is just a  of the function
of the function ![[(h)]_{Tree}](https://s0.wp.com/latex.php?latex=%5B%28h%29%5D_%7BTree%7D&bg=ffffff&fg=000000&s=0&c=20201002) . So, now our graphic is:
. So, now our graphic is:![map~[(h)]_{Tree}](https://s0.wp.com/latex.php?latex=map%7E%5B%28h%29%5D_%7BTree%7D&bg=ffffff&fg=000000&s=0&c=20201002) :
:![map~[(h)]_{Tree}~:~[(Int \times~Int)] \rightarrow~[Tree(Int \times~Int)]](https://s0.wp.com/latex.php?latex=map%7E%5B%28h%29%5D_%7BTree%7D%7E%3A%7E%5B%28Int+%5Ctimes%7EInt%29%5D+%5Crightarrow%7E%5BTree%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
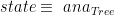 where
where 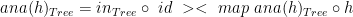





 that means ‘def’ from ‘definition’. I can’t use ‘def’ in this LaTeX package. And I confess that didn’t investigate a lot about that, in matter of fact I like the output of
that means ‘def’ from ‘definition’. I can’t use ‘def’ in this LaTeX package. And I confess that didn’t investigate a lot about that, in matter of fact I like the output of  combinator defined in
combinator defined in  is often called ’either’. This is the combinator responsible to take care of union’s (eithers in Haskell).
is often called ’either’. This is the combinator responsible to take care of union’s (eithers in Haskell).








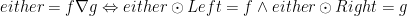




 and
and 




 combinator
combinator










 combinator have more precedence than the
combinator have more precedence than the  combinator.
combinator.






