First I would like to introduce the notation that I use here. The pointfree notation is good to see a program (functions) data flow and as composition of functions, combination of functions, if you prefer. This style is characterized by not using variables in declaration of functions. Haskell allow us to implement that notation natively. The dual of the pointfree notation is the pointwise one.
A simple example of a function in pointwise style:
f n = (n+2)*10 -- pointwise
The dual in pointfree would be:
f = (*10) . (+2) -- pointfree
Clarifications
First of all to define a function, for example 

I will assume that you are familiarized with infix notation, 

Types
For this post I need to explain the data type we will going to use. In Haskell we define it by:
data Tree a = Node a [Tree a]
Let’s create the same, but more convenient. Consider the following isomorphic type for 
data Tree a = Node (a, [Tree a])
We could see 
Node :: (a, [Tree a]) -> Tree a
So typologically we have ![(a, [Tree~a])](https://s0.wp.com/latex.php?latex=%28a%2C+%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
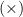
Now we can say that 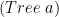
![(a \times~[Tree~a])](https://s0.wp.com/latex.php?latex=%28a+%5Ctimes%7E%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
This is something to say that ![(Tree~a) \cong~(a \times~[Tree~a])](https://s0.wp.com/latex.php?latex=%28Tree%7Ea%29+%5Ccong%7E%28a+%5Ctimes%7E%5BTree%7Ea%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
Anamorphisms
Let 



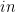

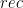
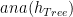

We use the notation 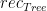

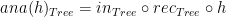
The function that we want is 
ana :: (A -> B) -> A -> Tree c
Type 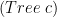
function in
The function 
inTree :: Tree a -> (a, [Tree a]) inTree = Node
In Haskell we represent the type 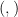

![D \sim c \times~[Tree~c]](https://s0.wp.com/latex.php?latex=D+%5Csim+c+%5Ctimes%7E%5BTree%7Ec%5D&bg=ffffff&fg=000000&s=0&c=20201002)
function
The function
Suppose that the pair of positive integers (v, p) denotes the number of red balls (v) and black (p) that is inside a bag, the balls which are taking randomly, successively, until the bag is empty.
This is the point-wise version of the function we want to convert to pointfree using anamorphisms. This function represent as a tree, all possible states of the bag over these experiences.
state :: (Int,Int) -> Tree (Int,Int) state(0,0) = Node (0,0) [] state(v,0) = Node (v,0) [state(v-1,0)] state(0,p) = Node (0,p) [state(0,p-1)] state(v,p) = Node (v,p) [state(v-1,p),state(v,p-1)]
If we want that “latex state$ became an anamorphism, we have to say that our type 


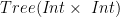
![(Int \times~Int) \times~[Tree (Int \times~Int)]](https://s0.wp.com/latex.php?latex=%28Int+%5Ctimes%7EInt%29+%5Ctimes%7E%5BTree+%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![[( h )]](https://s0.wp.com/latex.php?latex=%5B%28+h+%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
function rec
Here we have to get a function ![(Int \times~Int) \times~[Tree~(Int \times~Int)]](https://s0.wp.com/latex.php?latex=%28Int+%5Ctimes%7EInt%29+%5Ctimes%7E%5BTree%7E%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
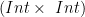
![[Tree~(Int \times~Int)]](https://s0.wp.com/latex.php?latex=%5BTree%7E%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)

![[(h)]_{Tree}](https://s0.wp.com/latex.php?latex=%5B%28h%29%5D_%7BTree%7D&bg=ffffff&fg=000000&s=0&c=20201002)
As you can see, the second part of the co-domain of ![map~[(h)]_{Tree}](https://s0.wp.com/latex.php?latex=map%7E%5B%28h%29%5D_%7BTree%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![map~[(h)]_{Tree}~:~[(Int \times~Int)] \rightarrow~[Tree(Int \times~Int)]](https://s0.wp.com/latex.php?latex=map%7E%5B%28h%29%5D_%7BTree%7D%7E%3A%7E%5B%28Int+%5Ctimes%7EInt%29%5D+%5Crightarrow%7E%5BTree%28Int+%5Ctimes%7EInt%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
So our final graphic became:
Now, we just have to define the function
h :: (Int, Int) -> ( (Int, Int), [ (Int, Int) ] ) h(0,0) = ( (0,0), [] ) h(v,0) = ( (v,0), [ (v-1,0) ] ) h(0,p) = ( (0,p) [ (0,p-1) ] ) h(v,p) = ( (v,p), [ (v-1,p), (v,p-1) ] )
And this is it! Now we can say that:
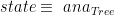
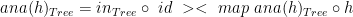
Outroduction
Here is all the code you need to run this example in Haskell:
module AnamorphismExample where infix 5 >< i1 = Left i2 = Right p1 = fst p2 = snd data Tree a = Node (a, [Tree a]) deriving Show split :: (a -> b) -> (a -> c) -> a -> (b,c) split f g x = (f x, g x) (><) :: (a -> b) -> (c -> d) -> (a,c) -> (b,d) f >< g = split (f . p1) (g . p2) inTree :: (a, [Tree a]) -> Tree a inTree = Node anaTree h = inTree . (id >< map (anaTree h)) . h -- our function h_gen :: (Int, Int) -> ( (Int, Int), [ (Int, Int) ] ) h_gen(0,0) = ( (0,0), [] ) h_gen(v,0) = ( (v,0), [ (v-1,0) ] ) h_gen(0,p) = ( (0,p) , [ (0,p-1) ] ) h_gen(v,p) = ( (v,p), [ (v-1,p), (v,p-1) ] ) state = anaTree h_gen
Pass a year since I promised this post. The next will be on hylomorphisms I promise not take too that much.







[…] Hylomorphisms in Haskell 9 04 2009 If you miss something in this post, I suggest you to start in Catamorphisms and Anamorphisms. […]
Can your repost the code? Looks like the html ate it.
Done! In fact the WordPress don’t like “<“, don’t know why…
[…] 9 04 2009 If you lost yourself in this post, I advise you to start in catamorphisms, then anamorphisms and then […]
[…] Anamorphisms in Haskell First I would like to introduce the notation that I use here. The pointfree notation is good to see a program […] […]
[…] Anamorphisms in Haskell « Ulisses Costa Blog (tags: haskell mathematics programming research anamorphism) […]