Recursion
In Haskell we essentially use recursion, this mean defining a function using itself definition.
A recursive function is, for example the factorial:

in haskell we define it like that:
fact 0 = 1 fact n = n * fact (n-1)
As you can see Haskell is authentic mathematic, pure functional language.
My point here is to show you the magic of the function 
ok…
Seeing the magic
The definition of the function 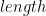
length [] = 0 length (h:t) = 1 + length t
The definition of the function 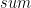
sum [] = 0 sum (h:t) = h + sum t
And the definition of the function 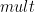
mult [] = 1 mult (h:t) = h * mult t
As you can see in all three definitions we have a pattern and we can generalize it:
functionName [] = stopCase functionName (h:t) = constant operator (functionName t)
We always need the stopping case of the function!
And the same happens in other functions like 
reverse [] = [] reverse (h:t) = reverse t ++ [h]
In this case we have:
functionName [] = stopCase functionName (h:t) = (functionName t) operator constant
So, we will always use the function applied to the tail of the list!
If we use some of lambda notation we can see one more pattern, the real one:
sum [] = 0 sum (h:t) = (a b -> a + b) h (sum t) reverse [] = [] reverse (h:t) = (a b -> b ++ [a]) h (reverse t)
Our lambdas functions have arity 2, because those are the parts in which we can see the lists (head + tail).
Now we can generalize even more, considering 
functionName [] = stopCase functionName (h:t) = function h (functionName t)
well, that’s not right for Haskell. Because it doesn’t know what 
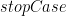
functionName function stopCase [] = stopCase
functionName function stopCase (h:t)
= function h (functionName function stopCase t)
Et voilá.
In fact the last definition is the true one for
Functions with foldr’s
Well… Now we can redefine previous functions just with foldr’s:
length l = foldr (a b -> 1 + b) 0 l sum l = foldr (+) 0 l mult l = foldr (*) 1 l reverse l = foldr (a b -> b ++ [a]) [] l
And all the functions over list’s…
and l = foldr (&&) True l or l = foldr (||) False l
More magic
Foldr is more magical than this, it is one catamorphism! A Catamorphism over this data type:
data [a] = [] | a : [a]
Haskell List’s!
That means that
Foldr also allows you to use Pointfree notation, witch I like. Formal explanation.
length = foldr (a b -> 1 + b) 0
More foldr’s
We can also write foldr’s functions to every data type that we create, and “explain” how recursive patterns works for our new data type:
data BTree a where
Empty :: BTree a
Node :: a -> BTree a -> BTree a -> BTree a
foldrBTree :: (a -> b -> b -> b) -> b -> BTree a -> b
foldrBTree op k Empty = k
foldrBTree op k (Node a l r) = op a (foldrBTree op k l) (foldrBTree op k r)
Now if we have a Binary Tree and want to know how many nodes it has, we just have to do this:
countNodes = foldrBTree (\a nodesLeft nodesRight ->a+nodesLeft+nodesRight) 0
If we want to know how many Empty’s our tree has:
countEmpty = foldrBTree (\_ nodesLeft nodesRight -> nodesLeft + nodesRight) 1
and so on…
Fold’s are really a genuine help for your code.
Later on I will talk more about catamorphisms…







Hi,
I liked your post it’s best explanation for foldr i have seen on the web for newbies
I still have a doubt though , how did you replace
functionName with functionName function stopCase
in the end would you care to elaborate on that
Thanks
Hi. Good post, but you should try removing more points from your functions. “sum l = foldr (+) 0 l” becomes “sum = foldr (+) 0”, “and l = foldr (&&) True l” becomes “and = foldr (&&) True”, etc.
I think the ‘any’ and ‘all’ functions deserve some further comment. The fact that laziness gives you early-out on those is interesting.
brilliant. now go write a dx10 video game with ur awesome language…
You should also take a look at UU’s Attribute Grammar System. It is a preprocessor for Haskell which is based on the idea of catamorphisms, and allows you to easily fold over lots of data-types. It comes in very handy for writing compilers or transforming large tree-like data-structures.
http://www.cs.uu.nl/wiki/HUT/AttributeGrammarSystem
Nitpicks: did you intend ‘lenght’ and to write “Foldr also allow you to use Pointfree notation, wish I like.”
Did some of this post get truncated?
I only see it up to the definition of ‘fact’..
In response about some critics of my English, just letting you know that I wrote this post in English to reach a vast audience . I think that you can get the whole idea, and the most important part of this is the technical explanation.
Even so I corrected all of the errors.
@Praj
f a = b
what is b? you have to receive “b”, so:
f a b = b
hope that I made that clear to you.
@Chris Eidhof
I’ll check that out. Thank you
@Keebler
That’s already corrected. Thanks
@Nick
I know… I used that on countNodes and countEmpty… I just did that to be more comprehensive.
I think it’s also important to mention that foldr will not necessarily go to the end of the list before returning a result, making it suitable for processing infinite lists. The *and* and *or* functions are good examples, since both will return as early as possible from a call.
Well done Eng. Ulisses
[…] revelam o sítio onde ele deveria realmente estar a programar os seus internacionalmente famosos foldrs. E viva os catamorfismos de listas! […]
I think Graham Hutton have an article called “A tutorial on the universality and expressiveness of fold” which is worthwhile to read if you are not very familiar to this topic.
“or l = foldr (||) False l” should be “or l = foldr (||) False 0”, shouldn’t it?
foldr (||) False :: [Bool] -> Bool
so the third argument of foldr must be, in this case, [Bool] not Int (0).
Loved this article, really helped out. Any chance of fixing the formatting a little? I bet a lot of people have this bookmarked; it’s a great post for new functional programmers.
done
Implementations of aggregators (such as length, sum, all, any, mult, etc) with foldr IS inefficient and irrational, because you can use efficient foldl instead. Even better, use strict version of left fold: foldl’. Why?
1. The implementation of foldl is tail-recursive, so it is optimised with tail call optimisation (TCO).
2. foldl’, in addition to foldl, haven’t deferred computations – chunks for updating accumulator values. So, we will NOT get stack overflow at “length [1..1000000]”.
(for details see http://www.haskell.org/haskellwiki/Performance/Accumulating_parameter)
foldr is useful when we have deal with structural transformations from one list to another (such as map, filter, etc), because the implementation of foldr (as opposed to foldl) allows to handle infinite lists.
Nikolay I think you miss the point here. My idea with this post was to make an introduction to high-order functions and traversals in Haskell. Like you can see in my other posts related to Haskell or theoretical foundations. I just used the foldr example because it seems more natural to me than foldl.
Of course foldl is way more efficient that foldr, and the only thing you need to draw this conclusion is read the code of foldr and foldl. So I think I owe you up to congratulate for you having read the code.
Either way I gave you a perfect score if it were a lesson.
foldr is also useful when we are dealing with lazy operators such as and (foldr and True listofbools). foldl always consume the whole list so that’s why you are mentioning foldr for structural transformations but it’s not just for that :-).
Great explanation! Thanks a lot!!
Just one suggestion: Please don’t use the small L as a variable identifier because it looks exactly like the number 1.